Nedlasting av data om kjøretøy
-
topic:wrote-on, /post/271, 2022-01-21T21:18:29.517Z Sist endret av En tidligere bruker
Målet er å lage noe statistikk rundt enkelte kjøretøymodeller. Har brukt Microsoft Access og Excel, og begge har begrensning på antall rader. Å kjøre filen gjennom grep er en mulighet for å gjøre dem mindre før import, men filtreringen der er jo ganske simpel.
-
topic:wrote-on, /post/274, 2022-01-24T19:13:01.899Z Sist endret av livar.bergheim
Her er oppskrift på korleis du filtrerer ut ei delmengde av datasettet ved hjelp av q, så du kan jobbe vidare med det i andre verktøy.
Forutsetningar: q er installert og du har lasta ned kjøretøy-datasettet (kjoretoy.csv)
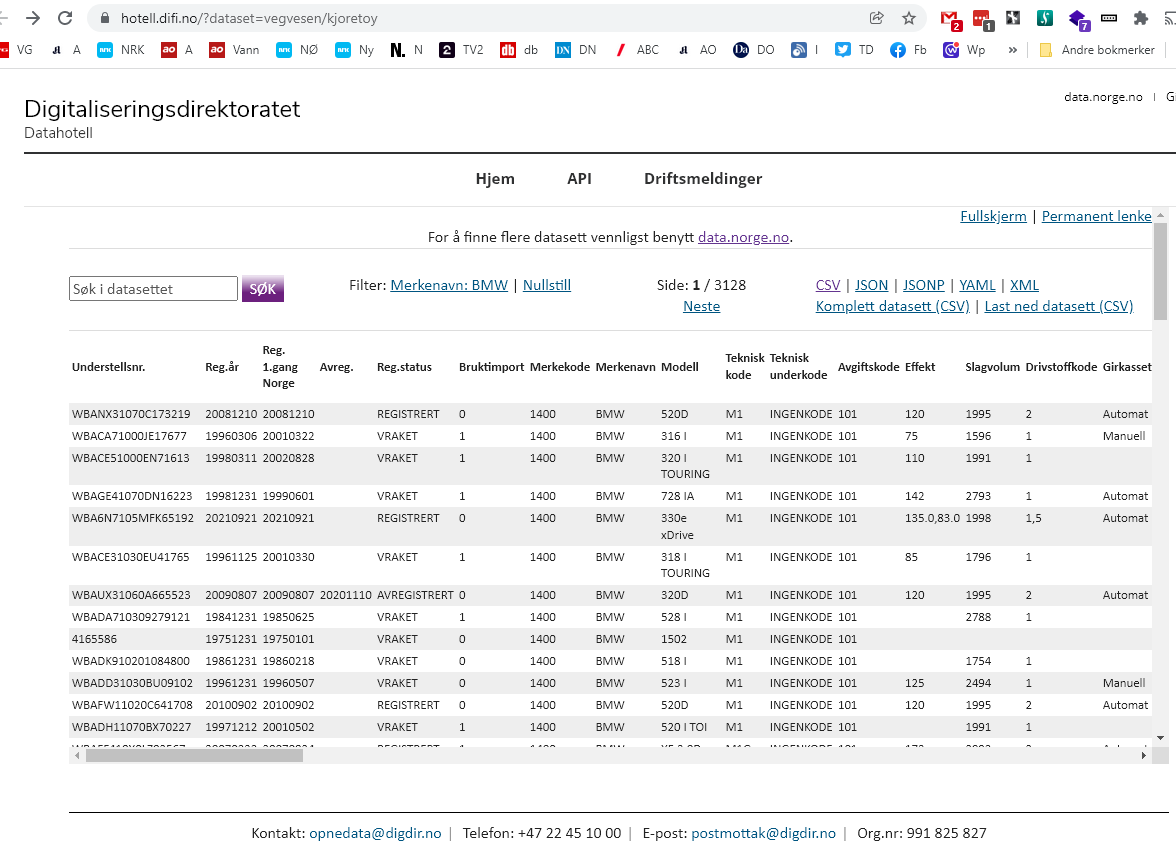
Først kan du sjekke kor mange rader utvalget gir. Her med merkenamn = "BMW", som i skjermbildet i første posten din.
q -C readwrite -H -O --delimiter=\; "SELECT COUNT(*) FROM kjoretoy.csv WHERE tekn_merkenavn = 'BMW'"Svaret er 286 833 treff, og det er godt under grensa på ca. 1 million rader i Excel.
Neste steg er å lagre delmengda til ei ny fil (kjoretoy_bmw.csv):
q -C read -H -O --delimiter=\; "SELECT * FROM kjoretoy.csv WHERE tekn_merkenavn = 'BMW'" > kjoretoy_bmw.csvI første kommandoen opprettar ein også ei cache-fil (parameter: -C readwrite) som gjer at vidare kommandoar på samme datasett går mykje fortare ved bruk av cache (parameter: -C read). Første kommandoen tok ca. 10 minutt hos meg, mens 2. kommando tok eit halvt minutt. Dersom eg køyrer første kommandoen på nytt med cache, så tar det rundt 5 sekund.
Cache-fila tar ein del diskplass - om lag like mykje som sjølve datasettet.
OBS! Dersom ein opnar ei CSV-fil direkte i Excel, så vil Excel gjette kva datatypar det enkelte felt/kolonne har. Det kan føre til at data blir endra til feil datatype (f.eks. tal blir datoar). For å unngå at Excel rotar til dataene, kan ein først opne Excel, og deretter importere CSV-fila. Brønnøysundregistrene har skrive tips om dette på sine nettsider (under "Korrigere formatfeil i CSV-dokumentet").
-
topic:wrote-on, /post/280, 2022-01-27T11:14:19.743Z Sist endret av
Fungerer dessverre ikke hos meg. Får feilmelding. Kan det være fordi det ser ut til å være noe grums i starten av csv filen?
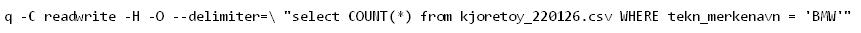
query error: no such column: tekn_merkenavn
Warning - There seems to be a "no such column" error, and -H (header line) exists.
Please make sure that you are using the column names from the header line and not the default (cXX) column names. Another issue might be that the file contains a BOM. Files that are encoded with UTF8 and contain a BOM can be read by specifying -e utf-9-sig in the command line. Support for non-UTF8 encoding will be provided in the future.Har så prøvd med
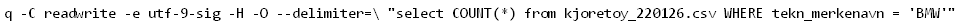
men da får jeg feilmelding: Encoding utf-9-sig could not be found
-
Fungerer dessverre ikke hos meg. Får feilmelding. Kan det være fordi det ser ut til å være noe grums i starten av csv filen?
query error: no such column: tekn_merkenavn
Warning - There seems to be a "no such column" error, and -H (header line) exists.
Please make sure that you are using the column names from the header line and not the default (cXX) column names. Another issue might be that the file contains a BOM. Files that are encoded with UTF8 and contain a BOM can be read by specifying -e utf-9-sig in the command line. Support for non-UTF8 encoding will be provided in the future.Har så prøvd med
men da får jeg feilmelding: Encoding utf-9-sig could not be found
topic:wrote-on, /post/281, 2022-01-27T11:40:57.866Z Sist endret av livar.bergheim@sven_bruun sa i Nedlasting av data om kjøretøy:
Fungerer dessverre ikke hos meg. Får feilmelding. Kan det være fordi det ser ut til å være noe grums i starten av csv filen?
Ser ut til at det manglar semikolon på delimiter-parameteret. Kan dette vere feilen?
«--delimiter=\» skal vere «--delimiter=\;»Om det ikkje fungerer, så kan du prøve å laste ned fila utan BOM.
Dersom ein brukar parameteret "?download" ved nedlasting av heile datasettet frå Datahotellet, så får ein med BOM (Byte Order Mark). Å ha med BOM ser ut til å hjelpe dersom ein vil opne fila direkte i Excel. Dersom ein ikkje har behov for BOM, så bør ein laste ned utan.Dei to alternative nedlastinglenkene er:
https://hotell.difi.no/download/vegvesen/kjoretoy?download - med BOM
https://hotell.difi.no/download/vegvesen/kjoretoy - utan BOM -
topic:wrote-on, /post/282, 2022-01-27T16:58:40.317Z Sist endret av
Prøvde med et semikolon der først, men da fikk jeg feilmeldingen:
Delimiter must be one character only -
Prøvde med et semikolon der først, men da fikk jeg feilmeldingen:
Delimiter must be one character onlytopic:wrote-on, /post/297, 2022-02-04T12:39:32.387Z Sist endret av@sven_bruun sa i Nedlasting av data om kjøretøy:
Prøvde med et semikolon der først, men da fikk jeg feilmeldingen:
Delimiter must be one character onlyDet ein må gjere er å oppgje semikolon som separator i q-kommandoen. Eg køyrte kommandoen på min Macbook, og måtte nytte skråstrek for å unnsleppe (escape) semikolon som fungerer som skilje mellom to separate kommandoar. Ut frå feilmeldinga frå q som du nemner, så har tydelegvis q fått inn meir enn eitt teikn. Har ikkje noko godt råd for korleis å få det til hos deg om det ikkje fungerer med kun semikolon eller med skråstrek i tillegg.
-
topic:wrote-on, /post/303, 2022-02-08T10:07:35.292Z Sist endret av
Eg spurte også på Twitter om tips til korleis jobbe med store CSV-filer og fekk mange svar:
https://twitter.com/livarb/status/1480534725429276672Har ikkje rukke å oppsummere svara her - endå.
-
topic:wrote-on, /post/305, 2022-02-09T09:27:23.071Z Sist endret av
Jeg har brukt Go med kun standard-biblioteket en del de siste årene for første behandling av store CSV-filer (og sammenstillng av Excel gjennom excelize biblioteket). Go er minne-effektivt med utf-8 internt, og med litt parallell kjøring kan man iterere relativt hurtig på noen GB. I senere tid er Copilot tjenesten til github nyttig og gjør at man kan skrive kommentarer som "UFT-16 with BOM transformer encoding" fremfor å lete i dokumentasjonen (Men, det blir jo litt kodelinjer, så det er ikke noe man alltid ønsker å dra frem)
Dette er egentlig ikke noen erstatning for Pandas i python eller tidyverse i R.
Google BigQuery er ganske rimelig når datasettet blir stort.
-
topic:user-referenced-topic-on, L livar.bergheim, /post/327,
-
Jeg kan ambefalle q (http://harelba.github.io/q/) som en enkelt SQL databasen direkte mot CSV filen. Som sagt vi jobber mye med kjøretøy databasen og har flere interne API. Kanskje vi kan hjelpe med.
topic:wrote-on, /post/627, 2022-12-15T13:54:09.693Z Sist endret av@robert-sasak sa i Nedlasting av data om kjøretøy:
Jeg kan ambefalle q (http://harelba.github.io/q/) som en enkelt SQL databasen direkte mot CSV filen. Som sagt vi jobber mye med kjøretøy databasen og har flere interne API. Kanskje vi kan hjelpe med.
-
Når man prøver å laste ned csv-data om kjøretøy så får man så store filer at mine verktøy ikke greier å behandle dem (flere GB).
Løsningen ser ikke ut til å støtte at man kun laster ned de dataene man spesifiserer i filteret på visningssiden? Noen tips til hvordan dette kan løses?https://data.norge.no/datasets/a8533876-cca7-4417-90be-b368f7d9542c
 topic:wrote-on, /post/968, 2024-01-28T18:33:27.137Z Sist endret av
topic:wrote-on, /post/968, 2024-01-28T18:33:27.137Z Sist endret av@sven_bruun Bruker linken https://hotell.difi.no/download/vegvesen/kjoretoyinfo?download til å analysere bilparken, men det ser ikke ut til at denne informasjonen er vedlikeholdt lenger. Hvor kan jeg finne fila med alle biler?
Hei! Det ser ut til at du er interessert i denne tråden, men du er ikke innlogget.
Lei av å måtte skrolle gjennom de samme innleggene hver gang du besøker siden? Når du er innlogget, kommer du alltid tilbake til nøyaktig der du var sist, og du kan velge å bli varslet om nye svar (via e-post eller push-varsel). Du kan også lagre bokmerker og gi tommel opp til innlegg for å vise andre i fellesskapet at du setter pris på bidragene deres.
Med ditt bidrag kan denne tråden bli enda bedre 💗
Registrer Logg inn