Whisper - transkribering
-
topic:wrote-on, /post/669, 2023-03-07T10:31:14.254Z Sist endret av tov.are.jacobsen
Hei,
Jeg har brukt Whisper.cpp en del de siste dagene og har hatt god nytte av det, selv om det blir en god del feil som må rettes.
Vår IT-avdeling har laget noen enkle nytte-scripts for å jobbe med whisper lokalt på maskinen fra shell (Mac): https://github.com/navikt/whisper-transcribe-shell
For å få det hele til å fungere må whisper legges i katalogen under:
https://github.com/ggerganov/whisper.cpp- init.sh for å kompilere og laste ned den største modellen.
- Legg mp4-filen i data-mappen.
- Kjør med run.sh
Dette er samme teknologi som UiO har laget som en intern tjeneste. Det er kjempespennende at slik teknologi har blitt mer tilgjengelig.
-
topic:wrote-on, /post/670, 2023-03-07T14:15:40.238Z Sist endret av
Takk for deling! Kanskje til nytte for å tekste og legge ut fleire møter, webinarer og liknande. Skal tipse kollegaer internt i Digdir.
Såg artikkel i Digi.no om liknande arbeid ved Universitetet i Oslo (UiO).
17.02.2023: «Bygde tjeneste som sparer dem for 20 millioner i året: − Dette er ny og sjokkerende teknologi» (krev abonnement)Dei skryt av at dei utvikla dette på rekordtid fordi Whisper er gjort tilgjengeleg som open kjeldekode, og at tekstane som blir generert frå lyd er på eit mykje høgare nivå enn med tidlegare løysingar, og handterer dialekter godt.
Korleis er køyretida på dette når ein køyrer lokalt på eiga maskin?
-
Takk for deling! Kanskje til nytte for å tekste og legge ut fleire møter, webinarer og liknande. Skal tipse kollegaer internt i Digdir.
Såg artikkel i Digi.no om liknande arbeid ved Universitetet i Oslo (UiO).
17.02.2023: «Bygde tjeneste som sparer dem for 20 millioner i året: − Dette er ny og sjokkerende teknologi» (krev abonnement)Dei skryt av at dei utvikla dette på rekordtid fordi Whisper er gjort tilgjengeleg som open kjeldekode, og at tekstane som blir generert frå lyd er på eit mykje høgare nivå enn med tidlegare løysingar, og handterer dialekter godt.
Korleis er køyretida på dette når ein køyrer lokalt på eiga maskin?
topic:wrote-on, /post/671, 2023-03-07T14:25:44.680Z Sist endret av tov.are.jacobsen@livar-bergheim Her er ett eksempel fra et møte på 56 minutter. Dette tok 96 minutter (Jeg har en 2018-modell av macbook pro med Core i5, så det går nok kjappere på noe nyere)
whisper_print_timings: fallbacks = 1 p / 1 h whisper_print_timings: load time = 5637.30 ms whisper_print_timings: mel time = 15318.44 ms whisper_print_timings: sample time = 13265.51 ms / 15886 runs ( 0.84 ms per run) whisper_print_timings: encode time = 3197293.50 ms / 131 runs (24406.82 ms per run) whisper_print_timings: decode time = 2556895.50 ms / 15882 runs ( 160.99 ms per run) whisper_print_timings: total time = 5788981.00 ms -
Takk for deling! Kanskje til nytte for å tekste og legge ut fleire møter, webinarer og liknande. Skal tipse kollegaer internt i Digdir.
Såg artikkel i Digi.no om liknande arbeid ved Universitetet i Oslo (UiO).
17.02.2023: «Bygde tjeneste som sparer dem for 20 millioner i året: − Dette er ny og sjokkerende teknologi» (krev abonnement)Dei skryt av at dei utvikla dette på rekordtid fordi Whisper er gjort tilgjengeleg som open kjeldekode, og at tekstane som blir generert frå lyd er på eit mykje høgare nivå enn med tidlegare løysingar, og handterer dialekter godt.
Korleis er køyretida på dette når ein køyrer lokalt på eiga maskin?
topic:wrote-on, /post/678, 2023-03-09T21:26:19.890Z Sist endret av tov.are.jacobsenVG sin Mac-applikasjon er nå gratis tilgjengelig i AppStore:
Skal ha spart de over 3000 timer siden rett før jul.
Det som er bra med denne applikasjonen er støtten for å velge en linje i grensesnittet og høre det tilhørende lydsporet med mulighet til å rette opp feil i selve grensesnittet.
-
topic:wrote-on, /post/822, 2023-08-30T07:48:19.010Z Sist endret av livar.bergheim
Nokon som har testa Nasjonalbiblioteket sin Whisper-modell og kan dele erfaringar?
«Knekker dialektkoden for språkmodeller» 08.08.2023 Digi.no (abb.)
Pressemelding frå Nasjonalbiblioteket 29.06.2023
Modellen delt på HuggingFaceTesta vanleg Whisper på opptak av Faglig arena for datadeling og informasjonsforvaltning tidlegare i år og det var vel mange feil, sjølv om det var veldig bra. Blant dei meir fornøyelege feila: «enhetsregisteret» --> «eneste registeret». Spent på kor mykje betre Nasjonalbiblioteket sin versjon er.
-
Nokon som har testa Nasjonalbiblioteket sin Whisper-modell og kan dele erfaringar?
«Knekker dialektkoden for språkmodeller» 08.08.2023 Digi.no (abb.)
Pressemelding frå Nasjonalbiblioteket 29.06.2023
Modellen delt på HuggingFaceTesta vanleg Whisper på opptak av Faglig arena for datadeling og informasjonsforvaltning tidlegare i år og det var vel mange feil, sjølv om det var veldig bra. Blant dei meir fornøyelege feila: «enhetsregisteret» --> «eneste registeret». Spent på kor mykje betre Nasjonalbiblioteket sin versjon er.
topic:wrote-on, /post/842, 2023-09-15T11:49:03.553Z Sist endret avJeg har så vidt fått testet litt den modellen som heter NbAiLab/nb-whisper-large-beta og her er det en del positivt å melde, selv om det er en del feil.
Den er definit preget av materalet den er lært opp på og gjør en del forenklinger som er vanlig i undertekster, dette slår noen ganger positivt ut sammenlignet med vanlig whisper.
Jeg har begrenset erfaring med transformer pipelines fordi jeg tidligere kun har brukt whisper.cpp. Jeg skulle gjerne ha fått den til å lage flere varianter og bedt gpt-4 vurdere om setningen ga mening før den landet på et resultat men klarer p.t. ikke helt å se hvordan jeg kunne gjort noe slikt.
Eksempelet på siden var egentlig grei.. Det ble mye installasjon av forskjellige bibloteker og xcode m.m.for å få det til å fungere (og ikke minst huske på å gjøre noe med resultatet)
Det blir spennende å se hvor de tar dette videre, og jeg vil definitivt bruke litt litt mer tid på den.
-
topic:wrote-on, /post/1092, 2024-06-25T12:07:01.983Z Sist endret av
@tov-are-jacobsen Noko nytt hos deg og i NAV med bruk av Whisper?
Testa nett ut WhisperX med Nasjonalbiblioteket sin modell. Dei skal også ha kudos for å ha gjeve ein del tips i dokumentasjonen sin om korleis ein kan bruke modellen, enten det er Whisper CPP, WhisperX eller andre måtar.
Det fungerer mykje betre enn Whisper CPP. Typisk kom det hallusinasjonar når det var periodar utan tale i lydsporet:
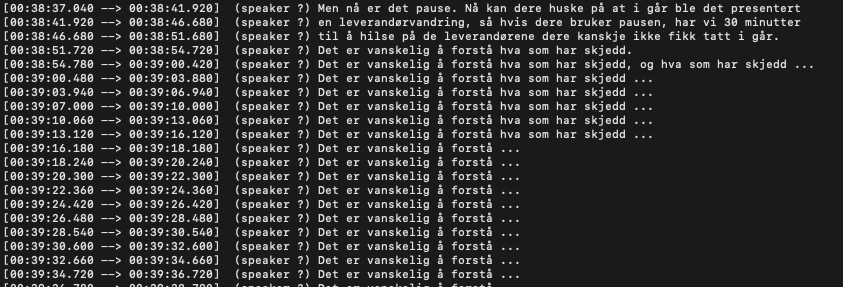
WhisperX, og sikkert andre løysingar, omgår problemet ved å først analysere kva deler av lydsporet som inneheld tale og kun køyre transkribering der det er tale.
Hei! Det ser ut til at du er interessert i denne tråden, men du er ikke innlogget.
Lei av å måtte skrolle gjennom de samme innleggene hver gang du besøker siden? Når du er innlogget, kommer du alltid tilbake til nøyaktig der du var sist, og du kan velge å bli varslet om nye svar (via e-post eller push-varsel). Du kan også lagre bokmerker og gi tommel opp til innlegg for å vise andre i fellesskapet at du setter pris på bidragene deres.
Med ditt bidrag kan denne tråden bli enda bedre 💗
Registrer Logg inn