Magasinstatistikk for norsk kraftproduksjon
-
topic:wrote-on, /post/527, 2022-09-23T11:54:38.404Z Sist endret av livar.bergheim
Når politikere, analytikere eller andre skal forklare, eller bortforklare
 , kraftprisene henvises det ofte til magasinfyllingen i norske vannmagasiner. Fordi vannkraften står for om lag 90-prosent av kraftproduksjonen i Norge, er fyllingsgraden eller lagret av vann viktig både for strømpriser og for at vi skal ha strøm når vi trenger den.
, kraftprisene henvises det ofte til magasinfyllingen i norske vannmagasiner. Fordi vannkraften står for om lag 90-prosent av kraftproduksjonen i Norge, er fyllingsgraden eller lagret av vann viktig både for strømpriser og for at vi skal ha strøm når vi trenger den.De underliggende dataene er enklere tilgjengelig enn hva mange kanskje tror. Norges vassdrags- og energidirektorat (NVE) har åpne API-er for disse datasettene som oppdateres ukentlig. I datakatalogen kan du finne veien til magasinstatistikk fra NVE. Mer informasjon om datasettet finnes her.
API-er for magasinstatistikk
Det er flere API-er fra denne statistikken. Her har vi to av de:-
https://nvebiapi.nve.no/api/Magasinstatistikk/HentOffentligDataMinMaxMedian. API-et gir et datasett over minimum-, maksimum- og medianverdier.
-
https://nvebiapi.nve.no/api/Magasinstatistikk/HentOffentligData. API-et gir et datasett med ca. 13 000 rader med ukentlig oppdatering siden 1995.
Disse dataene kan benyttes til mange formål og fremstillinger. Nedenfor viser vi et par eksempler.
Eksempel: Utvikling av fyllingsgraden for hele landet så langt i år
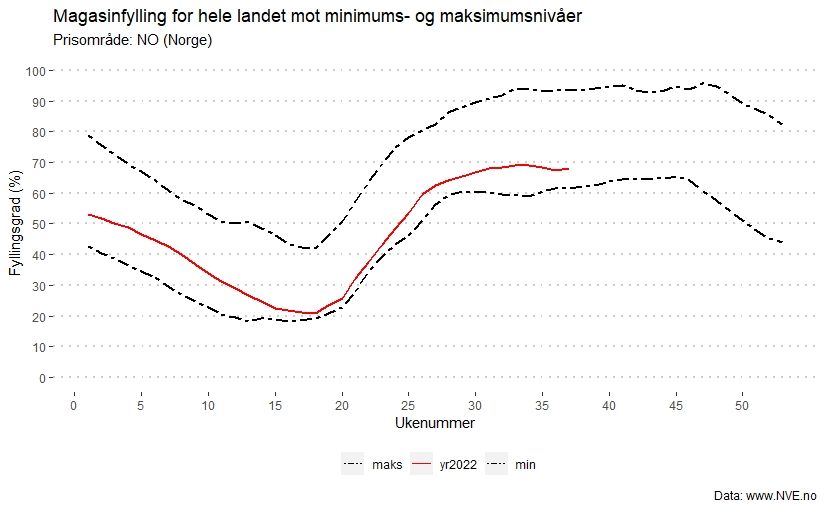
I grafen ser vi utviklingen av fyllingsgraden for Norge i år, mot historisk minimums- og maksimumsnivåer. Vi ser at fyllingsgraden i dag er rett under 70% for landet samlet sett.
Eksempel: Store variasjoner i fyllingsgrad mellom de ulike områdene
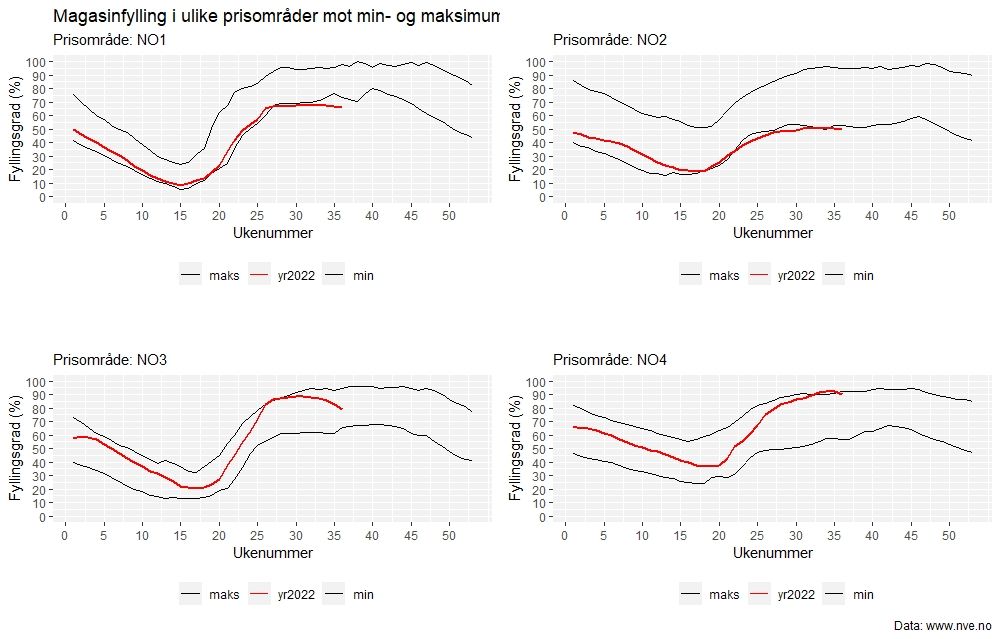
Grafene viser fyllingsgraden for ulike prisområder i Norge. For Østlandet (NO1) og Sør-Norge (NO2), de to øverste grafene, er det historisk lav fyllingsgrad. Det er situasjonen her som har bidratt til spekulasjonene om vi har nok vann til vinteren. For Nord-Norge (NO4) derimot, er det historisk høy fyllingsgrad på 90%. Disse variasjonene er ett viktig element til de store prisforskjellene en har sett mellom nord og sør.
Grafene er utarbeidet i R, men kan følgelig utarbeides i mange andre verktøy. Legger ved koden for de siste eksemplet, som sikkert har rom for forbedringer. Kom gjerne med andre fremstillinger eller eksempler.
#pakker(samlinger av funksjonalitet i R) for oppgaven NB! Må installeres først library(jsonlite) library(tidyverse) #inneholder bl.a. ggplot2 som vi benytter for plot library(httr) library(gridExtra) #for flere plot #1) Henter inn datasettene dat1 <- "https://nvebiapi.nve.no/api/Magasinstatistikk/HentOffentligDataMinMaxMedian" %>% fromJSON() #datasett over min, max og median dat2 <- "https://nvebiapi.nve.no/api/Magasinstatistikk/HentOffentligData" %>% fromJSON() #datasett over magasinfylling siden 1995 med ca 13000 rader #2) Strukturerer data df1 <- dat1[dat1$omrType %in% c("EL"), ] df1 <- df1[,c(2,3,4,8)] colnames(df1)<- c("omrnr","Uke", "min", "maks") df1 <- gather(df1, Aar, fyllingsgrad, min:maks, factor_key = FALSE) df2 <- dat2[dat2$omrType %in% c("EL"), ] df2 <- df2[,(3:6)] colnames(df2) <- c("omrnr","Aar","Uke","fyllingsgrad") df2 <- df2[df2$Aar %in% c(2022), ] df2$Aar = paste0('yr', df2$Aar) df3 <- bind_rows(df1, df2) #lager en tabell av df1 og df2 #3)Lager og formaterer plot (det som er felles). Benytter ggplot-pakken. p1 <- ggplot(df3, aes(x = Uke, y = fyllingsgrad*100, colour = Aar, size = Aar))+ labs(x= "Ukenummer", y = "Fyllingsgrad (%)", size = 0.7)+ theme(panel.background = element_rect(fill="grey95"))+ theme(legend.position = "bottom",legend.justification="top", legend.title = element_blank())+ scale_x_continuous(breaks = seq(0, 52, by = 5))+ scale_y_continuous(breaks = seq(0, 100, by = 10), limits = c(0,100))+ scale_color_manual(values = c(maks = "black", yr2022 = "red", min = "black"))+ scale_size_manual(name= "", values = c(maks = 0.7, yr2022 = 0.9, min = 0.7), guide = "none") #4) Lager de ulike plotene (dataene er forskjellig) for de ulike prisomraadene: NO1 <- p1 + geom_line(data = df3[df3$omrnr %in% c(1), ], ) + labs(title = "Magasinfylling i ulike prisomraader mot min- og maksimumsnivaer", subtitle = "Prisomraade: NO1", caption = "") NO2 <- p1 + geom_line(data = df3[df3$omrnr %in% c(2),], ) + labs(title = "", subtitle = "Prisomrade: NO2", caption = "") NO3 <- p1 + geom_line(data = df3[df3$omrnr %in% c(3), ], ) + labs(title = "", subtitle = "Prisomrade: NO3", caption = "") NO4 <- p1 + geom_line(data = df3[df3$omrnr %in% c(4), ], ) + labs(title = "", subtitle = "Prisomrade: NO4", caption = "Data: www.nve.no") #5) De ulike plotene: grid.arrange(NO1,NO2,NO3, NO4, nrow=2, ncol=2) -
Hei! Det ser ut til at du er interessert i denne tråden, men du er ikke innlogget.
Lei av å måtte skrolle gjennom de samme innleggene hver gang du besøker siden? Når du er innlogget, kommer du alltid tilbake til nøyaktig der du var sist, og du kan velge å bli varslet om nye svar (via e-post eller push-varsel). Du kan også lagre bokmerker og gi tommel opp til innlegg for å vise andre i fellesskapet at du setter pris på bidragene deres.
Med ditt bidrag kan denne tråden bli enda bedre 💗
Registrer Logg inn