Distribuere data via GitHub
-
topic:wrote-on, /post/1122, 2024-08-08T11:13:08.123Z Sist endret av livar.bergheim
Testar i samarbeid med Landbruksdirektoratet å legge ut datasett på GitHub, som alternativ til å legge ut datasett som filer andre stader, for eksempel web server.
https://github.com/datahotellet/ldir-testBakgrunnen er at Datahotellet skal leggast ned, og at det då er behov for å gjere datasett tilgjengeleg på andre måtar.
Enten utgjevarar av data som treng ein annan måte å distribuere data på. Vi i Digdir ser også på å bruke dette til å arkivere datasett på Datahotellet som ikkje blir oppdatert vidare slik at dei framleis er tilgjengelege.Med denne løysinga får ein eit greitt grensesnitt for å sjå på dataene og metadata (forklaring av felter m.m.) i nettlesaren, samtidig som ein kan laste ned heile datasettet.
Tar gjerne imot innspel og spørsmål.
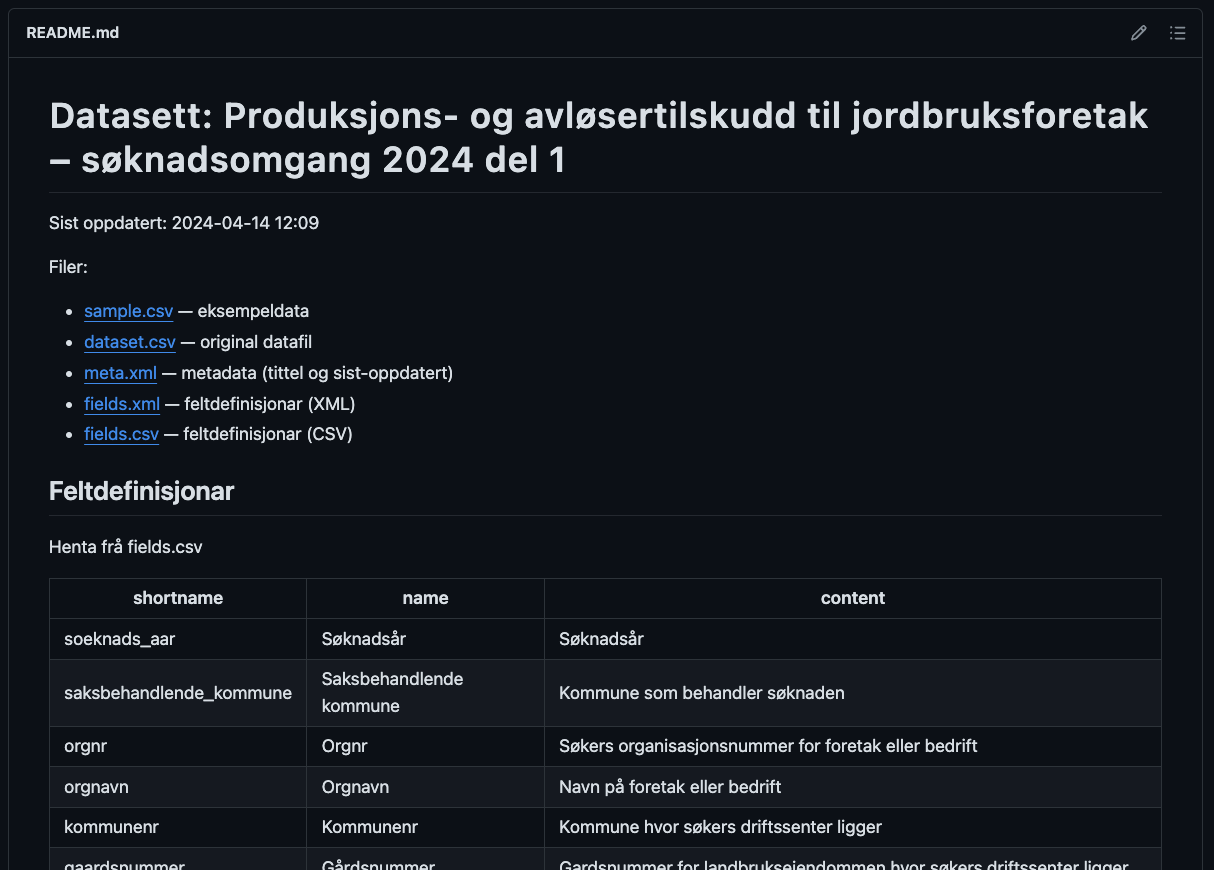
Eksempel på generert README-fil for eit datasett:
https://github.com/datahotellet/ldir-test/tree/main/datasets/produksjon-og-avlosertilskudd/2024 -
topic:wrote-on, /post/1128, 2024-08-22T10:05:26.394Z Sist endret av
Heisann, vi i Innovasjon Norge henter ned data fra Landbruksdirektoratet programmatisk. På denne måten blir det mulig for oss å hente data via GitHubs API, men så vidt jeg vet er ikke dette helt frem å gjøre det på den måten og ikke helt ideelt på samme måten som et åpent API med mer direkte adresser etc. Jeg hadde et par spørsmål og innspill i den forbindelse, nå er det jo litt tidlig i testingen og sånt så ikke sikkert dere har alle svarene og tanker enda
")
- Først og fremst lurte jeg på om dere vet om det er mulig å hente ned filene på en enklere måte enn ved å bruke GitHubs API
og så et par innspill
-
Dersom valget faller på GitHub er det mulig å ha det slik at den seneste dataen er på en fast "path" slik at det blir litt enklere å sette opp den automatiserte hentingen uten å måtte forholde seg til endringer i mappestruktur etc.
-
Siden dette er CSV filer, så kan man bruke versjoneringen til å lage "releases" av ny data, som også gjør det litt enklere for situasjoner som oss og lete seg tilbake i historikk osv. For å forklare litt nærmere så tenker jeg da at man kan ha en utgivelser for f.eks. «Melk» som da kan være 2024, 2025 osv.
Henger litt sammen med punkt 1 at man har en fast "path" for dataen og, da kan man «tracke releases» etc.
-
Heisann, vi i Innovasjon Norge henter ned data fra Landbruksdirektoratet programmatisk. På denne måten blir det mulig for oss å hente data via GitHubs API, men så vidt jeg vet er ikke dette helt frem å gjøre det på den måten og ikke helt ideelt på samme måten som et åpent API med mer direkte adresser etc. Jeg hadde et par spørsmål og innspill i den forbindelse, nå er det jo litt tidlig i testingen og sånt så ikke sikkert dere har alle svarene og tanker enda
- Først og fremst lurte jeg på om dere vet om det er mulig å hente ned filene på en enklere måte enn ved å bruke GitHubs API
og så et par innspill
-
Dersom valget faller på GitHub er det mulig å ha det slik at den seneste dataen er på en fast "path" slik at det blir litt enklere å sette opp den automatiserte hentingen uten å måtte forholde seg til endringer i mappestruktur etc.
-
Siden dette er CSV filer, så kan man bruke versjoneringen til å lage "releases" av ny data, som også gjør det litt enklere for situasjoner som oss og lete seg tilbake i historikk osv. For å forklare litt nærmere så tenker jeg da at man kan ha en utgivelser for f.eks. «Melk» som da kan være 2024, 2025 osv.
Henger litt sammen med punkt 1 at man har en fast "path" for dataen og, da kan man «tracke releases» etc.
topic:wrote-on, /post/1130, 2024-08-23T11:01:19.379Z Sist endret av@kristoffer-selvaer Takk for innspel
Kjenner ikkje godt nok til GitHub sitt API med tanke på kva mulegheter som er der.
Tanken er at dette erstattar å legge ut datasetta som filer på eigen nettstad, så det er ikkje tenkt at ein kan hente data på noko anna måte (oppslag, søk, filtrering) enn å laste ned heile datasettet. Antar at med GitHub sitt API så tenker du på å lese ut liste over mapper og filer som er i kodelageret (repository).- Direktelenker til filer
Tenker hovud-måten å hente data på er å peike direkte på rå-versjonen av CSV-filene. For eksempel:
https://raw.githubusercontent.com/datahotellet/ldir-test/main/datasets/leveransedata-melk/2023/dataset.csvOm du tenker på å oppdage nye datasett (til dømes at undermappa "2025" har dukka opp i ei mappe), så er det andre alternativ (sjå under).
- Korleis hente nyaste data
For datasetta som blir erstatta med ny versjon, til dømes foretak, er det berre å hente nye data frå samme URL.
Nokre av datasetta er tidsseriar, for eksempel leveransedata melk. Slik eg forstår det, ønskjer du å kunne peike mot nyaste datasettet i ein serie ved å peike til for eksempel ".../latest" i staden for å ha logikk for å avgjere at undermappa "2024" er nyaste datasettet. Eg trur dette blir litt rotete. Enten må ein kalle datasettet "2024" for "latest", og seinare endre namn til "2024" når det kjem nytt, eller så må ein duplisere mappene, så ein har både "2024" og "latest" med samme innhald.
Prøver ei anna løysing.
Har rigga ein ny fil, datasets.txt, som blir generert på roten av prosjektet.
Der er liste over alle datasett i repositoriet. På den måten kan ein lettare oppdage filer.
Kan det vere ein farbar veg?Elles skal det vere mogeleg å oppdage nye datasett ved å parse data-katalogen på data.norge.no. Akkurat no er det ikkje API-endepunkt som gir ut alle datasett inkludert distribusjonar, så i skrivande stund er heile katalogen kun tilgjengeleg i Turtle-format. Det er uansett ein omveg, og det er som regel noko forsinkelse frå data vert lagt ut til data-beskrivelse i data.norge er på plass, enten det er berre eit par timar eller par dagar.
- Releases i GitHub
Kan vere mogleg, men usikker på om det gir nok verdi til å forsvare ekstra kostnaden ved å måtte manuelt opprette releases i GitHub når det kjem nye datasett. Om ein gjer seg avhengig av dette, kan det også blir ei ekstra feilkjelde. Fort gjort å legge ut dataene men gløyme å opprette release.
Tenker det er betre framgangsmåte å oppdage at nye datasett (mapper) er dukka opp.
Skulle ein hatt opplegg med releases, kunne ein tenke seg å legge på tags for melk, egg, korn etc.
Utdjup gjerne vidare om du likevel trur det er verdt å sjå vidare på. -
topic:wrote-on, /post/1131, 2024-08-26T08:00:12.333Z Sist endret av
Takk for raskt svar!
Antar at med GitHub sitt API så tenker du på å lese ut liste over mapper og filer som er i kodelageret (repository).
Ja, det var egentlig eneste måten jeg visste om å hente ut filer fra GitHub. Disse direktelenkene til råfilene løser jo egentlig alle problemene sånn sett. Det viktigste var å slippe og forholde oss til GitHub APIene som jeg tenkte ville bli litt unødvendig hodebry for å hente ut filer.
Når det gjelder punkt to så tenkte jeg som du sier å ha noe type "./latest". Men jeg har gravd litt mer i eksisterende løsning og ser at vi har noe logikk for å håndtere årstallene i URLene på noen av disse leveransedataene. Ikke så veldig elegant sånn sett, men vi sjekker bare på mulige årstall det kan være data for og henter ned dataen på den måten allerede. Så det kan vi fortsette å gjøre siden det fungerer i dag, så trenger vi ikke å lage mer arbeid enn vi trenger.
Med disse direktelenkene og forutsigbare serier så har vi det slik som i dag, så da er vi fornøyde
- Releases i GitHub
Kan vere mogleg, men usikker på om det gir nok verdi til å forsvare ekstra kostnaden ved å måtte manuelt opprette releases i GitHub når > det kjem nye datasett. Om ein gjer seg avhengig av dette, kan det også blir ei ekstra feilkjelde. Fort gjort å legge ut dataene men gløyme å > opprette release.
Tenker det er betre framgangsmåte å oppdage at nye datasett (mapper) er dukka opp.
Skulle ein hatt opplegg med releases, kunne ein tenke seg å legge på tags for melk, egg, korn etc.
Utdjup gjerne vidare om du likevel trur det er verdt å sjå vidare på.
Jeg ser absolutt den, det er jo noe med å lage en prosess rundt å lage releases nok til at det blir en stabil og sikker måte å løse det på. For vår del så er ikke dette noe game changer sånn sett, vi beholder nok de tidsbaserte triggerne våre så er ikke avhengig av at man får synkronisert med releases etc. var noen umiddelbare tanker rundt på kontoret på noe som kunne vært kult og ha når dere potensielt går over til GitHub.

-
topic:wrote-on, /post/1136, 2024-09-04T09:09:09.197Z Sist endret av
Kan nemne at Forskningsrådet vil legge ut sine to datasett i eit GitHub-kodelager.
Det gjeld Søknader til og innvilgede prosjekter og «Signerte kontrakter med norsk deltakelse i EUs rammeprogram for forskning og innovasjon Horisont 2020»
Kjem tilbake med meir informasjon når det er lagt ut. -
topic:user-referenced-topic-on, L livar.bergheim, /post/1143,
-
topic:wrote-on, /post/1192, 2024-11-20T21:00:22.489Z Sist endret av
Finnes det noen planer for å legge ut produsentnummer for landbruket (eksempelvis sammen med organisasjonsnummer)? Det står i datahotellet at Landbrukets dataflyt har overtatt ansvaret for dette. Men de tar 9 kroner pr. spørring (for ett nummer) + fast kostnad + etableringskostnad. Det synes jeg er veldig dyrt for noe som burde vært åpent /var gratis før.
-
Finnes det noen planer for å legge ut produsentnummer for landbruket (eksempelvis sammen med organisasjonsnummer)? Det står i datahotellet at Landbrukets dataflyt har overtatt ansvaret for dette. Men de tar 9 kroner pr. spørring (for ett nummer) + fast kostnad + etableringskostnad. Det synes jeg er veldig dyrt for noe som burde vært åpent /var gratis før.
topic:wrote-on, /post/1193, 2024-11-26T11:51:55.104Z Sist endret av@Per-Ivar-Skaanevik sa i Distribuere data via GitHub:
Finnes det noen planer for å legge ut produsentnummer for landbruket (eksempelvis sammen med organisasjonsnummer)? Det står i datahotellet at Landbrukets dataflyt har overtatt ansvaret for dette. Men de tar 9 kroner pr. spørring (for ett nummer) + fast kostnad + etableringskostnad. Det synes jeg er veldig dyrt for noe som burde vært åpent /var gratis før.
Godt spørsmål, men litt på sida av emnet for denne tråden. Denne tråden handlar om måten å distribuere data på, heller enn kva data som er med.
Kan du opprette som eigen tråd i Etterspør-kategorien? -
topic:wrote-on, /post/1226, 2025-01-03T06:56:10.211Z Sist endret av
Hei,
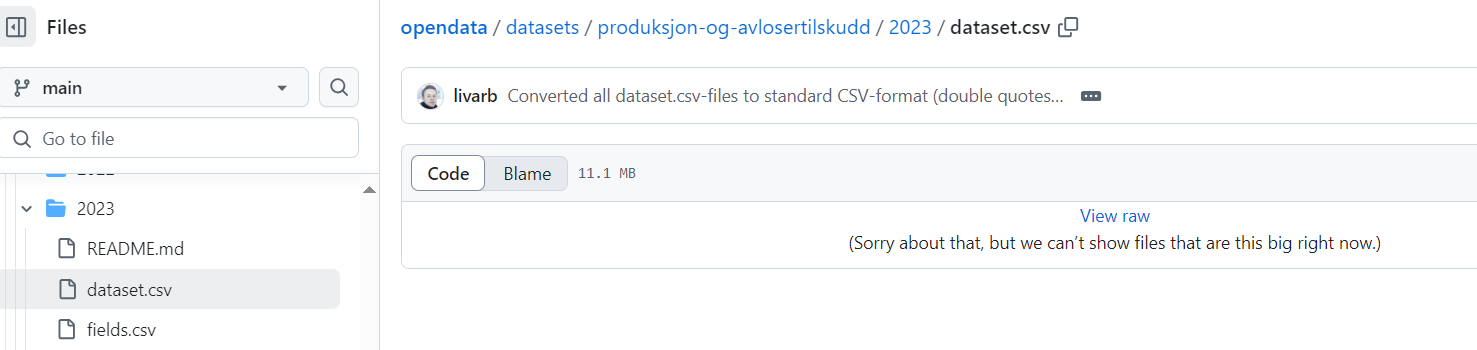
Når jeg prøver å laste ned filen dataset.csv får jeg beskjed om at filen er for stor.
Er dette en begrensning på min pc, eller er det en begrensning på filen ?Er det andre muligheter for å laste ned ? (gjelder dataset for produksjon-og-avløsertilskudd/202 - CSV fil)
-
Hei,
Når jeg prøver å laste ned filen dataset.csv får jeg beskjed om at filen er for stor.
Er dette en begrensning på min pc, eller er det en begrensning på filen ?Er det andre muligheter for å laste ned ? (gjelder dataset for produksjon-og-avløsertilskudd/202 - CSV fil)
topic:wrote-on, /post/1227, 2025-01-03T11:53:14.604Z Sist endret av@Halvor-Aarnes sa i Distribuere data via GitHub:
Hei,
Når jeg prøver å laste ned filen dataset.csv får jeg beskjed om at filen er for stor.
Er dette en begrensning på min pc, eller er det en begrensning på filen ?Er det andre muligheter for å laste ned ? (gjelder dataset for produksjon-og-avløsertilskudd/202 - CSV fil)
Hei,
Feilmeldingen i skjermbildet ditt er bare at filen i datasettet er for stor til å forhåndsvises i GitHub i nettleseren.
Du kan fint laste ned filen og åpne lokalt, for eksempel i ditt foretrukne rekneark-program.
Ein måte å gjøre det på er å høyre-klikke på «View raw» og velge Last ned, lagre filen lokalt og så åpne.
Håper dette hjelper
Hei! Det ser ut til at du er interessert i denne tråden, men du er ikke innlogget.
Lei av å måtte skrolle gjennom de samme innleggene hver gang du besøker siden? Når du er innlogget, kommer du alltid tilbake til nøyaktig der du var sist, og du kan velge å bli varslet om nye svar (via e-post eller push-varsel). Du kan også lagre bokmerker og gi tommel opp til innlegg for å vise andre i fellesskapet at du setter pris på bidragene deres.
Med ditt bidrag kan denne tråden bli enda bedre 💗
Registrer Logg inn